Business
October 28, 2025
Lessons from Building an AI Knowledge Assistant on Nigeria's Informal Economy

Chisom Ekwuribe

Adejoke Adekunle
How we built AI to make a fragmented, complex economy understandable, and what it taught us about AI that actually works.

We’ve been building AI tools and workflows for a while now; systems that streamline company processes, make data more usable, and help teams work smarter. Our recent project building a knowledge assistant on data about Nigeria’s informal economy came with a different kind of complexity.This time, we were creating a public-facing tool for a diverse audience with varying levels of context and expectation.
At its core, the project was about transforming a plethora of information into an experience that invites people to ask questions, get clear answers, and explore insights in ways traditional reports can’t. For us, it became a study in the thoughtful design of AI systems: balancing the depth of research with the simplicity of everyday conversation, and learning how to build tools that are both reliable and exciting to use.
We’re sharing our learnings to help organizations and builders exploring similar initiatives understand what it really takes to design AI systems that feel a little more human and a lot more helpful.
Reports Share Insights. People Search for Answers.
Reports do the heavy lifting; analyzing, summarizing and presenting facts. But even the best reports can’t anticipate or accommodate every question someone might have. Readers come with their own contexts, skipping between data points, comparing, and digging for specifics that matter to them.
Our goal was to bridge that gap by making exploration intuitive, and ensuring that when people searched for answers, they found reliable information and guidance to help shape real decisions.
Where Getting it Wrong With AI Has Consequences
Data about Nigeria’s informal economy is one such example where information shapes real decisions, both within and outside the country. It influences where investors place capital, how the government designs policies and interventions, and how development partners assess progress.
Each year, major institutions invest enormous effort in gathering and presenting this data. Our work built on publicly available insights from these efforts, designing a system that helps readers understand the scale and nuance of the informal sector.
In taking this work a step further, our challenge became: how do we make information about the informal economy more accessible? How do we personalize access to this vast body of knowledge so that a policymaker, investor, or entrepreneur can get tailored answers to their own questions and act with confidence? And, most importantly, how do we ensure the knowledge assistant provides consistently reliable answers? Because when data informs investment and policy, even a hallucinated stat can ripple into real-world impact.
The Hard Part Isn't the AI
Today, with all the tools at our disposal, anyone can build an AI tool, and "AI chatbot" suggests something straightforward. There's also a fair skepticism when someone announces an AI-powered anything. The assumption would be that the builder simply picked a large language model, fed it some documents, and hit deploy. In practice though, building one that actually works well is deceptively demanding.
The least glamorous part of this build was figuring out how to split the materials in the knowledge base. We started with a chunking strategy from a past project, assuming it would transfer neatly. It didn’t. What we learned was: every data resource has its own rhythm. Some get straight to the point. Others build context slowly. A chunk size that works beautifully for one can completely break another. It was a tedious exercise, but studying how different reports were structured, how stats were introduced and how stories unfolded around them, was what helped us find a chunking rhythm that made sense to the model.
That meant a lot of iteration. Every time we changed a chunk size or added a new source, we had to reload a large dataset into the vector database and start again. This manual, repetitive work taught us where the boundaries were. Too small, and the model couldn’t see enough context to answer, too large, and it drowned in irrelevant information and started hallucinating.
And if you’re wondering how large language models manage to process trillions of pages without anyone manually slicing up documents; well, they do it too, just differently. LLMs automatically break text into chunks during training to learn general language patterns at scale. Our focus instead was to help the model interpret the informal economy data accurately; designing rules that preserved context, reduced hallucination, and ensured every answer pointed back to the right source.
We applied the same rigour to retrieval where we tested how many results to pull per query, five, six, eight etc, watching how each setting shifted both speed and accuracy.
So yes, “AI processes documents fast yadda yadda yadda” sounds easy in theory. But you don’t really appreciate how much grunt work goes into making it feel easy until you build one yourself.
Models are a Minefield
Every model comes with trade-offs, and they can dramatically alter a tool’s behaviour. On paper, the differences between models seem minor. In practice, they’re not.
We tested several options from different providers on our use case. The smaller models were faster but often glossed over nuance or missed key figures. Reasoning models handled complexity better but were noticeably slower. There were moments when we’d test and just feel the pain of time crawling while we waited for answers even though, in reality, it was only a few seconds. No, thanks.
In our model selection, we measured three core metrics:
Speed: how quickly a user could get a complete response
Accuracy: how often the output matched the facts from our knowledge base
Reliability: how consistently the model stayed correct across different question types
Of the three, accuracy was non-negotiable. Every decision we made around model choice came back to that, and it guided how we interpreted the other two.
The model we landed on produced verifiable answers quickly enough to keep users engaged. It wasn’t the fastest, but it was consistently right >70% of the time, and that mattered more.
What we learned while searching for the best-fit model carried over to everything else we built after. Because once you’ve sat through those seconds of silence, you start to understand that accuracy alone isn’t enough.
People Want Tools to be Nice to Them
This was a surprise to us, though perhaps it shouldn’t have been.
We assumed accuracy was the primary driver of satisfaction; that if the knowledge assistant gave the right answer most of the time, users would be happy, even if the tone was blunt. But testing revealed that people wanted more. They wanted the assistant to sound considerate, to engage in a way that felt aware of the person behind the question.
So we started calibrating tone deliberately: warm enough that users felt seen, but grounded enough to stay credible. We also built in conversational memory so the assistant could understand follow-up questions in context. That feature turned out to be more valuable than we expected. People don’t ask questions in isolation; they ask, learn, and then dig deeper. Enabling that natural pattern of inquiry improved engagement and made the interaction feel more human.
When we went live, that design choice was validated almost immediately. Someone typed, “I am stressed.” The assistant responded empathetically, acknowledging their feelings before offering to help with questions related to the informal sector. It showed that people will always bring their humanity to the conversation, even when the tool’s job is to talk about data.
A Few Things We’d Tell Fellow Builders
For anyone designing knowledge assistants, these are the lessons we’d pass forward.
Don’t stop at prompting
There’s a ceiling to what you can fix with prompt engineering alone. Explore other levers such as chunking, retrieval parameters, and model selection. These often do more to improve accuracy and stability than another round of clever phrasing ever will. This is a good resource to reference.
Small prompt blocks can create big leaps
When you modularize your prompt, you can test and swap each block independently.
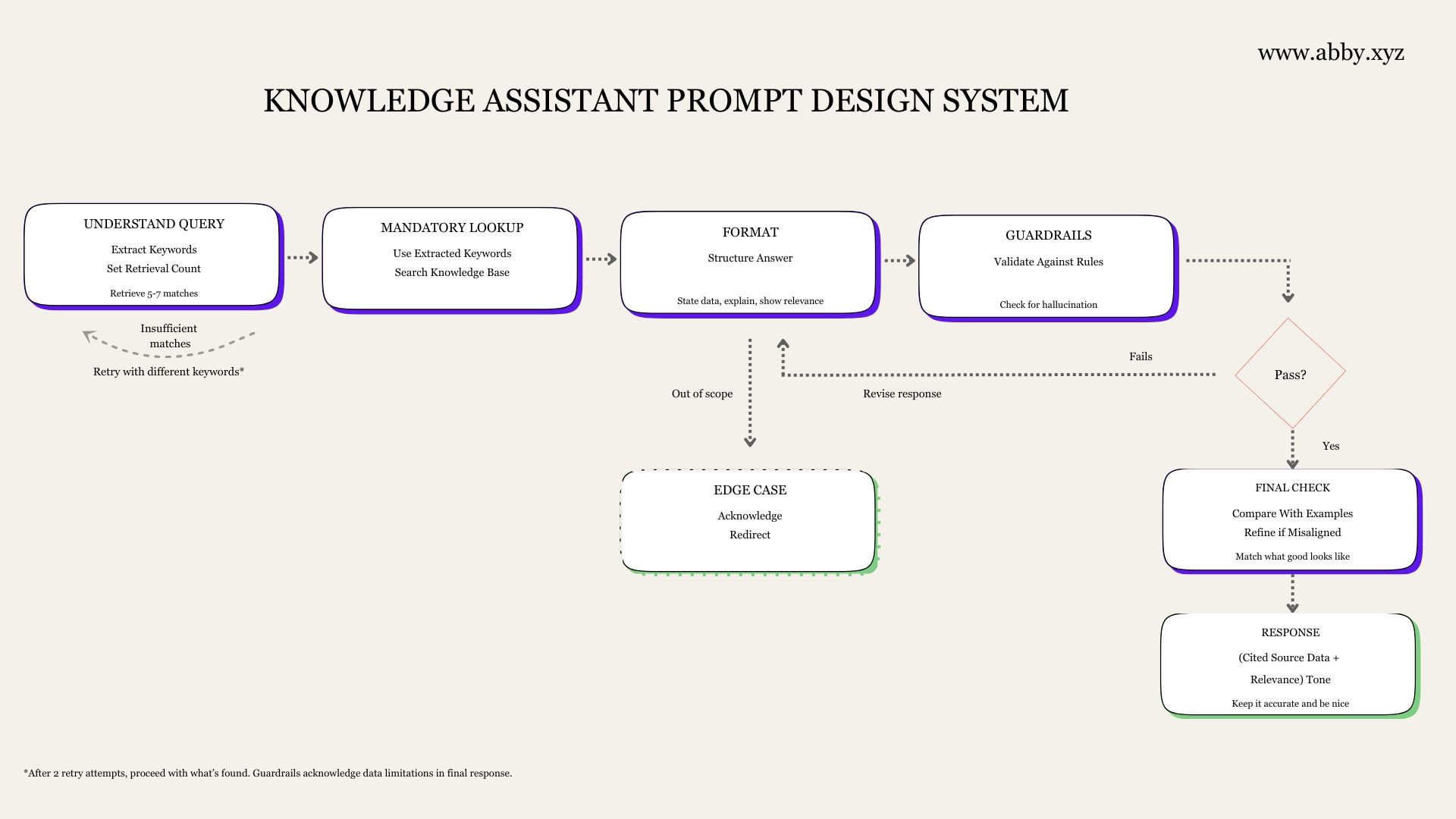
We layered ours into four sections:
Context setup: what the model should know about the task
Behaviour rules: how it should reason and decide
Answer style: tone and phrasing preferences
Output structure: the format to return
Being able to adjust one without breaking the others gave us speed and more control.
Retrieval discipline beats raw model power
When your context pipeline is clean, even a smaller model can return sharper, more consistent answers. Don’t throw compute at a problem that better retrieval design can solve.
Show the model what “good” looks like, but know your limits
Adding a handful of Q&A examples (5-10) in your prompt can dramatically improve output quality. Beyond that, you hit diminishing returns on speed and context length. Learn to tell when you’re optimizing at the margins versus actually solving the problem.
Where Knowledge Assistants Create Real Value
A knowledge assistant adds the most value when information is authoritative, complex, or difficult for people to explore on their own. As we built, we began seeing scenarios where one could meaningfully improve how people access and act on information.
Regulatory and Compliance Documentation
Organizations with complex guidelines or procedures can make that information less daunting. Someone trying to understand compliance requirements gets direct answers instead of searching through lengthy documents or waiting for internal clarifications.
Policy Delivery and Partner Coordination
When countries or multi-stakeholder networks work together on shared reform goals, knowledge assistants can play a pivotal role in tracking progress, comparing outcomes, and reporting to partners.
Take, for example, the Open Government Partnership, a global initiative of 75 member countries including the US, UK, Nigeria, Kenya, and Morocco. Each member co-creates action plans with civil-society partners to strengthen transparency, accountability, and participation. A knowledge assistant in this context could help ministers, local reform teams, and donor organizations instantly query what’s on track, what’s delayed, and what evidence supports each claim. This in turn preserves institutional memory, improves collaboration across borders, and helps governments project verified progress to their peers and the global community.
Improving Citizen Engagement and Public Participation
For countries working to strengthen transparency and participation, knowledge assistants can help bridge open-data infrastructure and real civic engagement. They turn large national data repositories into accessible entry points for everyday users.
Take Qatar, for example. Its Open Data Portal, operated by the National Planning Council, brings together socio-economic and environmental data across themes like population, energy, trade, and public services. We believe the goal here is to help people understand national progress and engage more directly with it.
A knowledge assistant built on top of this ecosystem could let residents ask questions such as, “What new health centres were opened this year?” or “How many young people are employed right now?” It could also guide them to open consultations, explain how to share feedback on new strategies, or help journalists compare changes in key indicators over time, while giving government teams a clearer view of which topics attract the most public interest.
Enhancing the Utility of Corporate Reporting
Reports like annual filings, ESG disclosures, and investor updates already attract attention. Analysts dissect them, journalists quote them, and advocacy groups spotlight what matters. Yet for many stakeholders, it’s simply not practical to read and cross-reference hundreds of pages each year. Most end up relying on expert interpretations rather than forming their own, because doing that work themselves is time-intensive and often inaccessible.
Knowledge assistants can change that. They let interested stakeholders explore these documents on their own terms, asking the questions that matter most to them. A minority shareholder might ask, “How have the company’s debt levels shifted since 2021?” An impact-focused investor might ask, “Which sustainability targets were missed, and why?” Instead of wading through years of PDFs, they get contextual, sourced answers that encourage independent, first-hand engagement.
——
For companies, this amplifies the effort already invested in preparing these reports, transforming static disclosures into living, explorable resources that strengthen transparency, accountability, and trust.
At their best, knowledge assistants don’t just make data easier to read, they help people think better and connect more meaningfully with the organizations they’re learning about. If you’re exploring how to bring more life to your organization’s data, we’d love to help. Send us a brief.
We’ve been building AI tools and workflows for a while now; systems that streamline company processes, make data more usable, and help teams work smarter. Our recent project building a knowledge assistant on data about Nigeria’s informal economy came with a different kind of complexity.This time, we were creating a public-facing tool for a diverse audience with varying levels of context and expectation.
At its core, the project was about transforming a plethora of information into an experience that invites people to ask questions, get clear answers, and explore insights in ways traditional reports can’t. For us, it became a study in the thoughtful design of AI systems: balancing the depth of research with the simplicity of everyday conversation, and learning how to build tools that are both reliable and exciting to use.
We’re sharing our learnings to help organizations and builders exploring similar initiatives understand what it really takes to design AI systems that feel a little more human and a lot more helpful.
Reports Share Insights. People Search for Answers.
Reports do the heavy lifting; analyzing, summarizing and presenting facts. But even the best reports can’t anticipate or accommodate every question someone might have. Readers come with their own contexts, skipping between data points, comparing, and digging for specifics that matter to them.
Our goal was to bridge that gap by making exploration intuitive, and ensuring that when people searched for answers, they found reliable information and guidance to help shape real decisions.
Where Getting it Wrong With AI Has Consequences
Data about Nigeria’s informal economy is one such example where information shapes real decisions, both within and outside the country. It influences where investors place capital, how the government designs policies and interventions, and how development partners assess progress.
Each year, major institutions invest enormous effort in gathering and presenting this data. Our work built on publicly available insights from these efforts, designing a system that helps readers understand the scale and nuance of the informal sector.
In taking this work a step further, our challenge became: how do we make information about the informal economy more accessible? How do we personalize access to this vast body of knowledge so that a policymaker, investor, or entrepreneur can get tailored answers to their own questions and act with confidence? And, most importantly, how do we ensure the knowledge assistant provides consistently reliable answers? Because when data informs investment and policy, even a hallucinated stat can ripple into real-world impact.
The Hard Part Isn't the AI
Today, with all the tools at our disposal, anyone can build an AI tool, and "AI chatbot" suggests something straightforward. There's also a fair skepticism when someone announces an AI-powered anything. The assumption would be that the builder simply picked a large language model, fed it some documents, and hit deploy. In practice though, building one that actually works well is deceptively demanding.
The least glamorous part of this build was figuring out how to split the materials in the knowledge base. We started with a chunking strategy from a past project, assuming it would transfer neatly. It didn’t. What we learned was: every data resource has its own rhythm. Some get straight to the point. Others build context slowly. A chunk size that works beautifully for one can completely break another. It was a tedious exercise, but studying how different reports were structured, how stats were introduced and how stories unfolded around them, was what helped us find a chunking rhythm that made sense to the model.
That meant a lot of iteration. Every time we changed a chunk size or added a new source, we had to reload a large dataset into the vector database and start again. This manual, repetitive work taught us where the boundaries were. Too small, and the model couldn’t see enough context to answer, too large, and it drowned in irrelevant information and started hallucinating.
And if you’re wondering how large language models manage to process trillions of pages without anyone manually slicing up documents; well, they do it too, just differently. LLMs automatically break text into chunks during training to learn general language patterns at scale. Our focus instead was to help the model interpret the informal economy data accurately; designing rules that preserved context, reduced hallucination, and ensured every answer pointed back to the right source.
We applied the same rigour to retrieval where we tested how many results to pull per query, five, six, eight etc, watching how each setting shifted both speed and accuracy.
So yes, “AI processes documents fast yadda yadda yadda” sounds easy in theory. But you don’t really appreciate how much grunt work goes into making it feel easy until you build one yourself.
Models are a Minefield
Every model comes with trade-offs, and they can dramatically alter a tool’s behaviour. On paper, the differences between models seem minor. In practice, they’re not.
We tested several options from different providers on our use case. The smaller models were faster but often glossed over nuance or missed key figures. Reasoning models handled complexity better but were noticeably slower. There were moments when we’d test and just feel the pain of time crawling while we waited for answers even though, in reality, it was only a few seconds. No, thanks.
In our model selection, we measured three core metrics:
Speed: how quickly a user could get a complete response
Accuracy: how often the output matched the facts from our knowledge base
Reliability: how consistently the model stayed correct across different question types
Of the three, accuracy was non-negotiable. Every decision we made around model choice came back to that, and it guided how we interpreted the other two.
The model we landed on produced verifiable answers quickly enough to keep users engaged. It wasn’t the fastest, but it was consistently right >70% of the time, and that mattered more.
What we learned while searching for the best-fit model carried over to everything else we built after. Because once you’ve sat through those seconds of silence, you start to understand that accuracy alone isn’t enough.
People Want Tools to be Nice to Them
This was a surprise to us, though perhaps it shouldn’t have been.
We assumed accuracy was the primary driver of satisfaction; that if the knowledge assistant gave the right answer most of the time, users would be happy, even if the tone was blunt. But testing revealed that people wanted more. They wanted the assistant to sound considerate, to engage in a way that felt aware of the person behind the question.
So we started calibrating tone deliberately: warm enough that users felt seen, but grounded enough to stay credible. We also built in conversational memory so the assistant could understand follow-up questions in context. That feature turned out to be more valuable than we expected. People don’t ask questions in isolation; they ask, learn, and then dig deeper. Enabling that natural pattern of inquiry improved engagement and made the interaction feel more human.
When we went live, that design choice was validated almost immediately. Someone typed, “I am stressed.” The assistant responded empathetically, acknowledging their feelings before offering to help with questions related to the informal sector. It showed that people will always bring their humanity to the conversation, even when the tool’s job is to talk about data.
A Few Things We’d Tell Fellow Builders
For anyone designing knowledge assistants, these are the lessons we’d pass forward.
Don’t stop at prompting
There’s a ceiling to what you can fix with prompt engineering alone. Explore other levers such as chunking, retrieval parameters, and model selection. These often do more to improve accuracy and stability than another round of clever phrasing ever will. This is a good resource to reference.
Small prompt blocks can create big leaps
When you modularize your prompt, you can test and swap each block independently.
We layered ours into four sections:
Context setup: what the model should know about the task
Behaviour rules: how it should reason and decide
Answer style: tone and phrasing preferences
Output structure: the format to return
Being able to adjust one without breaking the others gave us speed and more control.
Retrieval discipline beats raw model power
When your context pipeline is clean, even a smaller model can return sharper, more consistent answers. Don’t throw compute at a problem that better retrieval design can solve.
Show the model what “good” looks like, but know your limits
Adding a handful of Q&A examples (5-10) in your prompt can dramatically improve output quality. Beyond that, you hit diminishing returns on speed and context length. Learn to tell when you’re optimizing at the margins versus actually solving the problem.
Where Knowledge Assistants Create Real Value
A knowledge assistant adds the most value when information is authoritative, complex, or difficult for people to explore on their own. As we built, we began seeing scenarios where one could meaningfully improve how people access and act on information.
Regulatory and Compliance Documentation
Organizations with complex guidelines or procedures can make that information less daunting. Someone trying to understand compliance requirements gets direct answers instead of searching through lengthy documents or waiting for internal clarifications.
Policy Delivery and Partner Coordination
When countries or multi-stakeholder networks work together on shared reform goals, knowledge assistants can play a pivotal role in tracking progress, comparing outcomes, and reporting to partners.
Take, for example, the Open Government Partnership, a global initiative of 75 member countries including the US, UK, Nigeria, Kenya, and Morocco. Each member co-creates action plans with civil-society partners to strengthen transparency, accountability, and participation. A knowledge assistant in this context could help ministers, local reform teams, and donor organizations instantly query what’s on track, what’s delayed, and what evidence supports each claim. This in turn preserves institutional memory, improves collaboration across borders, and helps governments project verified progress to their peers and the global community.
Improving Citizen Engagement and Public Participation
For countries working to strengthen transparency and participation, knowledge assistants can help bridge open-data infrastructure and real civic engagement. They turn large national data repositories into accessible entry points for everyday users.
Take Qatar, for example. Its Open Data Portal, operated by the National Planning Council, brings together socio-economic and environmental data across themes like population, energy, trade, and public services. We believe the goal here is to help people understand national progress and engage more directly with it.
A knowledge assistant built on top of this ecosystem could let residents ask questions such as, “What new health centres were opened this year?” or “How many young people are employed right now?” It could also guide them to open consultations, explain how to share feedback on new strategies, or help journalists compare changes in key indicators over time, while giving government teams a clearer view of which topics attract the most public interest.
Enhancing the Utility of Corporate Reporting
Reports like annual filings, ESG disclosures, and investor updates already attract attention. Analysts dissect them, journalists quote them, and advocacy groups spotlight what matters. Yet for many stakeholders, it’s simply not practical to read and cross-reference hundreds of pages each year. Most end up relying on expert interpretations rather than forming their own, because doing that work themselves is time-intensive and often inaccessible.
Knowledge assistants can change that. They let interested stakeholders explore these documents on their own terms, asking the questions that matter most to them. A minority shareholder might ask, “How have the company’s debt levels shifted since 2021?” An impact-focused investor might ask, “Which sustainability targets were missed, and why?” Instead of wading through years of PDFs, they get contextual, sourced answers that encourage independent, first-hand engagement.
——
For companies, this amplifies the effort already invested in preparing these reports, transforming static disclosures into living, explorable resources that strengthen transparency, accountability, and trust.
At their best, knowledge assistants don’t just make data easier to read, they help people think better and connect more meaningfully with the organizations they’re learning about. If you’re exploring how to bring more life to your organization’s data, we’d love to help. Send us a brief.
We’ve been building AI tools and workflows for a while now; systems that streamline company processes, make data more usable, and help teams work smarter. Our recent project building a knowledge assistant on data about Nigeria’s informal economy came with a different kind of complexity.This time, we were creating a public-facing tool for a diverse audience with varying levels of context and expectation.
At its core, the project was about transforming a plethora of information into an experience that invites people to ask questions, get clear answers, and explore insights in ways traditional reports can’t. For us, it became a study in the thoughtful design of AI systems: balancing the depth of research with the simplicity of everyday conversation, and learning how to build tools that are both reliable and exciting to use.
We’re sharing our learnings to help organizations and builders exploring similar initiatives understand what it really takes to design AI systems that feel a little more human and a lot more helpful.
Reports Share Insights. People Search for Answers.
Reports do the heavy lifting; analyzing, summarizing and presenting facts. But even the best reports can’t anticipate or accommodate every question someone might have. Readers come with their own contexts, skipping between data points, comparing, and digging for specifics that matter to them.
Our goal was to bridge that gap by making exploration intuitive, and ensuring that when people searched for answers, they found reliable information and guidance to help shape real decisions.
Where Getting it Wrong With AI Has Consequences
Data about Nigeria’s informal economy is one such example where information shapes real decisions, both within and outside the country. It influences where investors place capital, how the government designs policies and interventions, and how development partners assess progress.
Each year, major institutions invest enormous effort in gathering and presenting this data. Our work built on publicly available insights from these efforts, designing a system that helps readers understand the scale and nuance of the informal sector.
In taking this work a step further, our challenge became: how do we make information about the informal economy more accessible? How do we personalize access to this vast body of knowledge so that a policymaker, investor, or entrepreneur can get tailored answers to their own questions and act with confidence? And, most importantly, how do we ensure the knowledge assistant provides consistently reliable answers? Because when data informs investment and policy, even a hallucinated stat can ripple into real-world impact.
The Hard Part Isn't the AI
Today, with all the tools at our disposal, anyone can build an AI tool, and "AI chatbot" suggests something straightforward. There's also a fair skepticism when someone announces an AI-powered anything. The assumption would be that the builder simply picked a large language model, fed it some documents, and hit deploy. In practice though, building one that actually works well is deceptively demanding.
The least glamorous part of this build was figuring out how to split the materials in the knowledge base. We started with a chunking strategy from a past project, assuming it would transfer neatly. It didn’t. What we learned was: every data resource has its own rhythm. Some get straight to the point. Others build context slowly. A chunk size that works beautifully for one can completely break another. It was a tedious exercise, but studying how different reports were structured, how stats were introduced and how stories unfolded around them, was what helped us find a chunking rhythm that made sense to the model.
That meant a lot of iteration. Every time we changed a chunk size or added a new source, we had to reload a large dataset into the vector database and start again. This manual, repetitive work taught us where the boundaries were. Too small, and the model couldn’t see enough context to answer, too large, and it drowned in irrelevant information and started hallucinating.
And if you’re wondering how large language models manage to process trillions of pages without anyone manually slicing up documents; well, they do it too, just differently. LLMs automatically break text into chunks during training to learn general language patterns at scale. Our focus instead was to help the model interpret the informal economy data accurately; designing rules that preserved context, reduced hallucination, and ensured every answer pointed back to the right source.
We applied the same rigour to retrieval where we tested how many results to pull per query, five, six, eight etc, watching how each setting shifted both speed and accuracy.
So yes, “AI processes documents fast yadda yadda yadda” sounds easy in theory. But you don’t really appreciate how much grunt work goes into making it feel easy until you build one yourself.
Models are a Minefield
Every model comes with trade-offs, and they can dramatically alter a tool’s behaviour. On paper, the differences between models seem minor. In practice, they’re not.
We tested several options from different providers on our use case. The smaller models were faster but often glossed over nuance or missed key figures. Reasoning models handled complexity better but were noticeably slower. There were moments when we’d test and just feel the pain of time crawling while we waited for answers even though, in reality, it was only a few seconds. No, thanks.
In our model selection, we measured three core metrics:
Speed: how quickly a user could get a complete response
Accuracy: how often the output matched the facts from our knowledge base
Reliability: how consistently the model stayed correct across different question types
Of the three, accuracy was non-negotiable. Every decision we made around model choice came back to that, and it guided how we interpreted the other two.
The model we landed on produced verifiable answers quickly enough to keep users engaged. It wasn’t the fastest, but it was consistently right >70% of the time, and that mattered more.
What we learned while searching for the best-fit model carried over to everything else we built after. Because once you’ve sat through those seconds of silence, you start to understand that accuracy alone isn’t enough.
People Want Tools to be Nice to Them
This was a surprise to us, though perhaps it shouldn’t have been.
We assumed accuracy was the primary driver of satisfaction; that if the knowledge assistant gave the right answer most of the time, users would be happy, even if the tone was blunt. But testing revealed that people wanted more. They wanted the assistant to sound considerate, to engage in a way that felt aware of the person behind the question.
So we started calibrating tone deliberately: warm enough that users felt seen, but grounded enough to stay credible. We also built in conversational memory so the assistant could understand follow-up questions in context. That feature turned out to be more valuable than we expected. People don’t ask questions in isolation; they ask, learn, and then dig deeper. Enabling that natural pattern of inquiry improved engagement and made the interaction feel more human.
When we went live, that design choice was validated almost immediately. Someone typed, “I am stressed.” The assistant responded empathetically, acknowledging their feelings before offering to help with questions related to the informal sector. It showed that people will always bring their humanity to the conversation, even when the tool’s job is to talk about data.
A Few Things We’d Tell Fellow Builders
For anyone designing knowledge assistants, these are the lessons we’d pass forward.
Don’t stop at prompting
There’s a ceiling to what you can fix with prompt engineering alone. Explore other levers such as chunking, retrieval parameters, and model selection. These often do more to improve accuracy and stability than another round of clever phrasing ever will. This is a good resource to reference.
Small prompt blocks can create big leaps
When you modularize your prompt, you can test and swap each block independently.
We layered ours into four sections:
Context setup: what the model should know about the task
Behaviour rules: how it should reason and decide
Answer style: tone and phrasing preferences
Output structure: the format to return
Being able to adjust one without breaking the others gave us speed and more control.
Retrieval discipline beats raw model power
When your context pipeline is clean, even a smaller model can return sharper, more consistent answers. Don’t throw compute at a problem that better retrieval design can solve.
Show the model what “good” looks like, but know your limits
Adding a handful of Q&A examples (5-10) in your prompt can dramatically improve output quality. Beyond that, you hit diminishing returns on speed and context length. Learn to tell when you’re optimizing at the margins versus actually solving the problem.
Where Knowledge Assistants Create Real Value
A knowledge assistant adds the most value when information is authoritative, complex, or difficult for people to explore on their own. As we built, we began seeing scenarios where one could meaningfully improve how people access and act on information.
Regulatory and Compliance Documentation
Organizations with complex guidelines or procedures can make that information less daunting. Someone trying to understand compliance requirements gets direct answers instead of searching through lengthy documents or waiting for internal clarifications.
Policy Delivery and Partner Coordination
When countries or multi-stakeholder networks work together on shared reform goals, knowledge assistants can play a pivotal role in tracking progress, comparing outcomes, and reporting to partners.
Take, for example, the Open Government Partnership, a global initiative of 75 member countries including the US, UK, Nigeria, Kenya, and Morocco. Each member co-creates action plans with civil-society partners to strengthen transparency, accountability, and participation. A knowledge assistant in this context could help ministers, local reform teams, and donor organizations instantly query what’s on track, what’s delayed, and what evidence supports each claim. This in turn preserves institutional memory, improves collaboration across borders, and helps governments project verified progress to their peers and the global community.
Improving Citizen Engagement and Public Participation
For countries working to strengthen transparency and participation, knowledge assistants can help bridge open-data infrastructure and real civic engagement. They turn large national data repositories into accessible entry points for everyday users.
Take Qatar, for example. Its Open Data Portal, operated by the National Planning Council, brings together socio-economic and environmental data across themes like population, energy, trade, and public services. We believe the goal here is to help people understand national progress and engage more directly with it.
A knowledge assistant built on top of this ecosystem could let residents ask questions such as, “What new health centres were opened this year?” or “How many young people are employed right now?” It could also guide them to open consultations, explain how to share feedback on new strategies, or help journalists compare changes in key indicators over time, while giving government teams a clearer view of which topics attract the most public interest.
Enhancing the Utility of Corporate Reporting
Reports like annual filings, ESG disclosures, and investor updates already attract attention. Analysts dissect them, journalists quote them, and advocacy groups spotlight what matters. Yet for many stakeholders, it’s simply not practical to read and cross-reference hundreds of pages each year. Most end up relying on expert interpretations rather than forming their own, because doing that work themselves is time-intensive and often inaccessible.
Knowledge assistants can change that. They let interested stakeholders explore these documents on their own terms, asking the questions that matter most to them. A minority shareholder might ask, “How have the company’s debt levels shifted since 2021?” An impact-focused investor might ask, “Which sustainability targets were missed, and why?” Instead of wading through years of PDFs, they get contextual, sourced answers that encourage independent, first-hand engagement.
——
For companies, this amplifies the effort already invested in preparing these reports, transforming static disclosures into living, explorable resources that strengthen transparency, accountability, and trust.
At their best, knowledge assistants don’t just make data easier to read, they help people think better and connect more meaningfully with the organizations they’re learning about. If you’re exploring how to bring more life to your organization’s data, we’d love to help. Send us a brief.
Latest blog posts

Achieve Your Business Goals
with Alexander Consulting!
Explore a dynamic user experience design project infused with financial management, investments, and profit-driven strategies. Dive into our elegantly crafted website, designed to empower users to invest intelligently with AI assistance.
87 %
reduction in hiring costs
Nolan Vaccaro
Director, Continental

91 %
Retention rate
Justin Rhiel Madsen
Design director, 3Lateral

Shape your organization’s next advantage with AI
Send a Brief
Shape your organization’s next advantage with AI
Shape your organization’s next advantage with AI
Send a Brief